
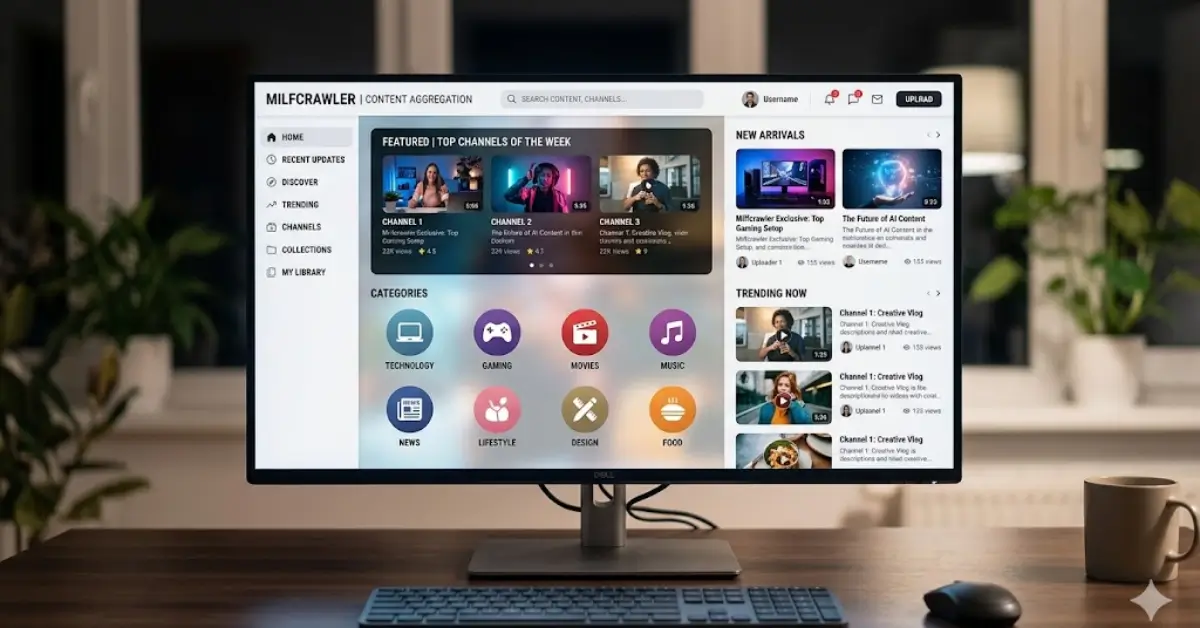
The internet contains countless platforms designed to organize and present information to users, yet milfcrawler represents a specific category of website that has generated significant curiosity among online audiences. Understanding milfcrawler requires moving beyond surface-level assumptions to recognize what these platforms truly do and how they function within the broader digital ecosystem. Milfcrawler operates as a content aggregation platform, which means it collects material from various sources and presents consolidated information in a single location. This approach fundamentally differs from traditional websites that create original content, making milfcrawler part of a growing category of platforms reshaping how users discover and consume information online.
The proliferation of milfcrawler-type platforms reflects changing user preferences regarding convenience and efficiency in content discovery. Rather than visiting multiple websites individually, users can visit milfcrawler to access organized collections in one place. This consolidation appeals to modern audiences accustomed to streamlined experiences and instant gratification. However, the simplicity milfcrawler presents to users masks complex systems operating behind the scenes. Automated tools scan content sources, indexing algorithms organize material, and engagement mechanics encourage continued browsing. Throughout this exploration, you will understand milfcrawler’s mechanics, implications, and the importance of informed, cautious engagement with such platforms.
What is Milfcrawler: Definition and Core Functionality
Milfcrawler is fundamentally a content aggregation platform that collects and displays material from diverse online sources through organized, easily navigable interfaces. Rather than creating original content, milfcrawler functions as a curator and organizer, gathering existing material and presenting it in categorized formats. The core functionality of milfcrawler involves systematic scanning of source websites, extracting relevant content, and reorganizing it in ways that facilitate user browsing. This aggregation approach creates value by eliminating the need for users to visit multiple sources individually. Milfcrawler achieves this through automated systems and algorithmic organization that continuously update and refine available content.
The defining characteristic of milfcrawler lies in its aggregation model rather than content production. While platforms like traditional websites invest in creating original material, milfcrawler focuses on discovery and curation. This distinction affects everything from content quality to legal and ethical considerations. Milfcrawler’s value proposition depends entirely on how effectively it organizes and presents content from other sources. The platform succeeds when users find milfcrawler more convenient than visiting multiple individual websites. Understanding this core functionality helps explain why milfcrawler exists, who uses it, and what risks or benefits it presents to different audiences.
How Milfcrawler Platforms Operate and Collect Content
The mechanics of milfcrawler content collection involve sophisticated automated systems working systematically to identify, extract, and organize material from across the internet. Automated crawlers scan websites continuously, identifying new content matching milfcrawler’s programmed criteria. These crawlers function like persistent robots, traveling through websites and recording information about available material. The data collected by milfcrawler’s crawlers includes metadata, descriptions, images, and links pointing back to original sources. This systematic collection happens continuously, allowing milfcrawler to maintain relatively current content offerings without manual intervention.
After collection, milfcrawler’s organization systems become crucial to the platform’s functionality. Indexing algorithms categorize collected content, making it searchable and browsable through organized structures. Milfcrawler uses various organizational approaches including category-based sorting, popularity-based ranking, and algorithmic recommendations. These systems determine which content appears prominently and which remains in secondary positions. Understanding how milfcrawler organizes content reveals that the platform doesn’t present all available material equally. Instead, algorithms prioritize certain content based on factors including user engagement, recency, and popularity metrics. This algorithmic curation significantly influences what users actually see when browsing milfcrawler.
The sustainability of milfcrawler depends on revenue models that justify the costs of maintaining massive data collection and organizational systems. Milfcrawler typically generates revenue through advertising, traffic generation, and engagement metrics. When users visit milfcrawler and click through to original content sources, the traffic flow benefits both the aggregator and original content creators. However, milfcrawler platforms also profit from the attention and data they accumulate from user browsing patterns. Understanding these economic factors reveals that milfcrawler’s operations aren’t altruistic but rather business models designed to generate profit from content aggregation and user engagement.
The User Experience on Milfcrawler
Users visiting milfcrawler encounter interface designs optimized for quick navigation and continuous engagement. The layout of milfcrawler typically emphasizes visual simplicity, allowing users to move intuitively between content categories without extensive learning curves. Content appears in organized grids, lists, or feed formats that facilitate rapid browsing. The user experience on milfcrawler deliberately encourages extended sessions, with recommended content suggestions and related material appearing throughout the interface. This design philosophy reflects the platform’s interest in maximizing user engagement metrics, which directly influence advertising value and platform profitability.
The convenience factor represents the primary appeal of milfcrawler for most users. Rather than conducting individual searches or visiting multiple websites, users find consolidated content addressing various interests. Milfcrawler’s organization eliminates the friction that users encounter on traditional search engines or portal sites. The time savings and effort reduction that milfcrawler provides make the platform appealing to busy individuals seeking efficient content discovery. However, this convenience comes with trade-offs. Extended browsing on milfcrawler often exceeds users’ initial intentions, as the platform’s design encourages “one more click” behavior. The seamless navigation and constant content suggestions create environments where time passes quickly without conscious awareness.
The user experience on milfcrawler also involves psychological elements reinforcing continued engagement. Browsing patterns establish habits that keep users returning to milfcrawler. The platform leverages principles of gamification, social proof, and algorithmic personalization to maintain user interest. Over time, users may find milfcrawler becoming a habitual destination for entertainment or information seeking. Understanding these behavioral mechanics helps users approach milfcrawler more consciously, preventing unintended excessive time investment or habituation that might undermine productivity or wellbeing.
Safety Concerns and Security Risks Associated with Milfcrawler
Browsing milfcrawler presents specific security risks that users should understand and actively mitigate. Content aggregation platforms like milfcrawler necessarily interact with countless external sources, some of which may contain malicious code, deceptive links, or harmful content. While milfcrawler attempts to filter dangerous material, no aggregation system perfectly prevents all threats. Users clicking links within milfcrawler risk encountering malware, phishing attempts, or exploitative content hosted on external sites. The decentralized nature of milfcrawler’s content sources means the platform cannot guarantee the safety of every link presented.
Pop-ups and unwanted advertisements represent another common security concern on milfcrawler platforms. Aggressive advertising networks sometimes inject intrusive elements into aggregation sites, creating poor user experience while potentially exposing users to unreliable advertisers. Some pop-ups carry malicious payloads disguised as legitimate advertisements. Users should be cautious about clicking unexpected advertisements or following suspicious calls-to-action that appear while browsing milfcrawler. Additionally, milfcrawler platforms may embed hidden scripts that track user behavior or attempt to exploit browser vulnerabilities. Keeping browsers and security software updated provides essential protection against these technical threats.
The nature of milfcrawler as an aggregation platform creates inherent challenges regarding content verification. Because milfcrawler doesn’t create content, it lacks the editorial oversight that legitimate news organizations maintain. This means milfcrawler may present misleading, false, or exploitative content without adequate fact-checking or verification. Users should approach all content encountered on milfcrawler with appropriate skepticism, recognizing that appearance of information on the platform doesn’t guarantee accuracy or reliability. Developing critical evaluation skills becomes essential when browsing milfcrawler or similar aggregation platforms.
Privacy Implications of Using Milfcrawler Platforms
Privacy concerns represent a significant consideration for users engaging with milfcrawler, as the platform necessarily tracks substantial amounts of user behavior data. Milfcrawler’s business model depends partly on understanding user preferences, interests, and browsing patterns. The platform collects data through cookies, tracking pixels, and user account information when users create profiles. This data accumulation allows milfcrawler to create detailed user profiles that inform algorithmic recommendations and targeted advertising. Users should understand that browsing milfcrawler generates records of their interests and preferences that the platform retains and potentially shares with advertisers or business partners.
The scope of data collection on milfcrawler extends beyond what many users realize or expect. Beyond content preferences, milfcrawler tracks information including device types, geographic locations, time of visit, and duration of engagement. This comprehensive data collection enables sophisticated behavioral prediction and targeting. Milfcrawler’s privacy policies typically permit the platform to use this data for internal purposes, advertising optimization, and potentially third-party sharing under certain circumstances. Users uncomfortable with this level of data collection should review milfcrawler’s privacy policies carefully and consider using privacy-enhancing tools when browsing.
Protecting privacy while using milfcrawler requires conscious effort and adoption of protective practices. Using private or incognito browsing modes prevents some forms of local tracking, though milfcrawler itself can still record activity. Virtual private networks (VPNs) mask user location and IP addresses, reducing milfcrawler’s ability to determine geographic data. Disabling cookies in browser settings prevents certain tracking mechanisms, though some functionality may be compromised. Users seeking maximum privacy protection while using milfcrawler should employ multiple protective measures simultaneously. Additionally, limiting personal information shared with milfcrawler minimizes the data available for targeted tracking and profiling.
Content Quality and Reliability on Milfcrawler
The quality of content presented on milfcrawler varies substantially due to the platform’s aggregation model. Because milfcrawler gathers material from diverse sources without consistent editorial standards, users encounter content ranging from high-quality to unreliable. Some material appearing on milfcrawler comes from reputable sources with established credibility, while other content originates from unknown or potentially dubious origins. Milfcrawler’s algorithms may present all content with equal prominence regardless of source reliability, making it difficult for users to distinguish trustworthy information from questionable material without careful evaluation.
The lack of editorial oversight on milfcrawler distinguishes it fundamentally from traditional media organizations that employ fact-checkers and editorial review processes. Milfcrawler’s automated systems cannot reliably distinguish between accurate reporting and misinformation. This gap in quality control means users encountering milfcrawler must apply individual critical thinking to evaluate content reliability. Users should consider source credibility when evaluating information found on milfcrawler, checking original sources directly rather than accepting content at face value. This additional effort becomes necessary precisely because milfcrawler’s aggregation approach doesn’t guarantee content quality.
Outdated or stale content sometimes appears on milfcrawler alongside current material. Aggregation systems may continue displaying content for extended periods after relevance declines or information becomes superseded by newer developments. Users relying on milfcrawler for time-sensitive information should verify publication dates and check for more recent sources. The algorithmic systems operating milfcrawler sometimes surface old content based on engagement metrics rather than currentness, potentially misleading users about information freshness. Developing habits of verification and source-checking becomes essential for responsible milfcrawler use.
Best Practices for Safe Milfcrawler Browsing
Maintaining security and privacy while using milfcrawler requires implementing multiple protective measures simultaneously. Users should maintain updated antivirus software and operating systems that defend against the malware and exploits that milfcrawler users may encounter. Browser security settings should be configured conservatively, with unnecessary plugins disabled and automatic downloads prevented. Installing reputable ad-blockers reduces exposure to potentially malicious advertisements while improving browsing experience. These technical safeguards provide foundational protection when accessing milfcrawler or similar platforms.
Behavioral practices complement technical protections when browsing milfcrawler safely. Users should avoid clicking suspicious links, unknown download buttons, or unexpected pop-ups appearing on milfcrawler. Hovering over links before clicking reveals destination URLs, helping identify potentially deceptive links. Users should refrain from entering personal information on milfcrawler or redirected external sites unless absolutely necessary. Passwords should be unique and strong, never shared with milfcrawler or other websites. These simple but consistent practices prevent many common online security failures that compromise user safety.
Critical evaluation of content encountered on milfcrawler should become automatic practice for regular users. Before trusting information found on milfcrawler, users should consider source credibility, check publication dates, and verify claims through independent sources. Recognizing that milfcrawler’s aggregation model doesn’t guarantee quality helps users approach all content with appropriate skepticism. When encountering surprising claims or emotionally provocative content on milfcrawler, healthy skepticism and additional verification become particularly important. Developing these evaluation habits transforms milfcrawler use from passive consumption to active, thoughtful engagement.
Privacy protection requires ongoing attention when using milfcrawler regularly. Users should review privacy settings periodically and adjust them to match personal comfort levels. Using privacy-focused tools including VPNs, encrypted browsers, and privacy extensions provides additional protection for users concerned about data collection. Understanding that milfcrawler collects data enables users to make informed decisions about engagement levels. Some users may choose to limit milfcrawler use specifically to protect privacy, while others may accept data collection in exchange for platform convenience. Either choice becomes valid when made consciously based on understanding actual practices.
Understanding Automation in Milfcrawler Systems
Automation represents the foundational technology enabling milfcrawler’s operations at scale. Without automated content crawling, collection, and organization systems, milfcrawler couldn’t possibly manage the volume of content required to provide comprehensive aggregation services. Automated crawlers operate continuously, scanning millions of websites for new content matching milfcrawler’s programmed criteria. This constant automation allows milfcrawler to maintain relatively current content without requiring large teams of manual content curators. The efficiency of automation enables the business model underlying milfcrawler platforms.
However, automation within milfcrawler systems also introduces limitations and potential errors. Automated systems cannot reliably understand context, nuance, or implied meaning the way human curators can. Milfcrawler’s algorithms may misclassify content, apply outdated categorizations, or fail to recognize problematic material. Automated quality control systems cannot consistently identify misinformation, manipulated content, or misleading presentations. This gap between automation capabilities and human judgment means milfcrawler inevitably misses important quality control functions. Users should understand these automated system limitations when evaluating content reliability on milfcrawler.
The algorithmic decision-making embedded within milfcrawler’s automation introduces subtle biases that influence what content users see. Algorithms optimized for engagement metrics may prioritize emotionally provocative content over accurate reporting. Popularity-based ranking systems amplify already-popular content while suppressing less-visible material. These algorithmic patterns can create filter bubbles where users see primarily content matching their existing preferences. Understanding that milfcrawler’s automation involves algorithmic decision-making rather than neutral presentation helps users recognize implicit biases in what the platform shows them.
Comparing Milfcrawler with Traditional Content Platforms
Milfcrawler’s aggregation model differs fundamentally from traditional content platforms that create original material. News organizations, blogs, and content creators invest resources in original research, writing, and verification. These platforms assume editorial responsibility for accuracy and appropriateness of published content. Traditional platforms typically employ fact-checkers, editors, and legal reviews that milfcrawler lacks. The differences between milfcrawler’s aggregation approach and traditional content creation affect reliability, accountability, and content quality substantially.
The economic models underlying milfcrawler and traditional platforms also differ significantly. Traditional content creators typically earn through subscriptions, advertising, or reader support. Milfcrawler generates revenue primarily through traffic generation, advertising, and data collection. These different economic incentives shape content decisions. Traditional platforms may sacrifice engagement to maintain credibility, while milfcrawler’s business model rewards engagement regardless of content quality. Understanding these economic differences explains some of the reliability gaps users notice when comparing milfcrawler with traditional media sources.
The user experience differs notably between milfcrawler and traditional platforms. Traditional platforms typically encourage deeper engagement with individual articles and primary sources. Milfcrawler encourages rapid browsing across numerous content items. These interface design differences reflect different content philosophies. Traditional platforms assume users want substantive content; milfcrawler assumes users want diverse options accessed quickly. Neither approach is inherently superior, but the differences matter for how users should approach each platform type.
Future Evolution and Trends in Milfcrawler-Type Platforms
The landscape of content aggregation platforms like milfcrawler continues evolving as technology advances and user expectations change. Improved artificial intelligence and machine learning may enable milfcrawler platforms to better understand content context and reliability. Enhanced algorithms could potentially improve content categorization and quality filtering. However, these technological improvements alone cannot fully address the fundamental challenges inherent in aggregation models. As milfcrawler and similar platforms mature, regulatory pressure regarding data privacy and content moderation will likely increase.
Regulatory scrutiny surrounding content aggregation platforms like milfcrawler is intensifying globally. Privacy regulations including GDPR in Europe and various state-level privacy laws in the United States constrain how milfcrawler can collect and use user data. Content moderation requirements increasingly affect how milfcrawler must address harmful material. Intellectual property concerns regarding content aggregation without explicit permission are creating legal challenges for milfcrawler-type platforms. These regulatory trends will likely force significant operational changes in how milfcrawler and comparable platforms function.
User awareness about aggregation platform mechanics and risks continues increasing. As more information about data collection and algorithmic manipulation becomes public, users approach platforms like milfcrawler with greater skepticism. This evolving user sophistication may prompt platforms like milfcrawler to adopt more transparent practices regarding data use and content curation. Alternatively, increased user caution may accelerate decline of aggregation platforms if users recognize the risks exceeding benefits. The future trajectory of milfcrawler-type platforms depends partly on how these services respond to increasing regulatory pressure and user scrutiny.
Frequently Asked Questions
What exactly is milfcrawler and how does it work?
Milfcrawler is a content aggregation platform that collects and displays material from various online sources in one organized location. It uses automated systems to continuously scan websites, gather content, and organize it into categories for easy browsing without users needing to visit multiple sources individually.
Is milfcrawler safe to use for browsing?
Milfcrawler can pose security risks including malware exposure through links and potentially harmful advertisements. Using updated security software, ad-blockers, and avoiding suspicious links provides protection. However, users should remain cautious and verify information from multiple sources.
What privacy concerns should I know about milfcrawler?
Milfcrawler tracks user browsing behavior, interests, and preferences to create detailed user profiles for targeted advertising. The platform collects location data, device information, and engagement metrics. Using private browsing modes, VPNs, and reviewing privacy settings provides some protection.
How reliable is the content on milfcrawler?
Content quality varies significantly on milfcrawler because the platform aggregates from diverse sources without consistent editorial oversight. Users should verify information through primary sources and consider source credibility rather than trusting all content equally.
Can I trust the information I find on milfcrawler?
Information on milfcrawler should be approached with skepticism and verified independently. The platform lacks the fact-checking and editorial review processes that traditional news organizations maintain, making verification essential.
CONCLUSION
Understanding milfcrawler requires recognizing both its practical conveniences and inherent risks. The platform provides efficient content aggregation that appeals to users seeking streamlined access to diverse material. However, milfcrawler’s aggregation model creates gaps in quality control, content verification, and editorial oversight that distinguish it from traditional content platforms. Users benefit from approaching milfcrawler with informed awareness of these characteristics rather than uncritical acceptance.
Security and privacy protection demand conscious effort when using milfcrawler regularly. Implementing technical safeguards, developing critical evaluation habits, and understanding data collection practices enable safer, more responsible engagement. Users should recognize that milfcrawler’s business model depends on user attention and data, influencing what content receives prominence and how the platform presents material. This awareness transforms milfcrawler use from passive consumption to active decision-making.
The future of milfcrawler and comparable platforms faces increasing regulatory scrutiny and evolving user sophistication regarding aggregation platform mechanics. Whether milfcrawler continues operating unchanged or adapts to new regulatory and user expectations remains uncertain. Regardless of future evolution, users engaging with milfcrawler today should implement protective practices and maintain healthy skepticism regarding content reliability. By approaching milfcrawler thoughtfully and cautiously, users can access its efficiency benefits while minimizing associated risks.